
Compania se deplasează pe accentul pe qubits, trecând la unitățile de calcul funcționale.
Va fi necesară o redare a ceea ce IBM va fi necesară pentru a adăposti un computer cuantic Starling. Credit: IBM
Marți, IBM și -a lansat planurile de construire a unui sistem care ar trebui să împingă calculul cuantic pe un teritoriu cu totul nou: un sistem care poate efectua ambele calcule utile în timp ce prinde și fixează erori și să fie complet imposibil de modelat folosind metode de calcul clasice. Hardware -ul, care se va numi Starling, este de așteptat să poată efectua 100 de milioane de operații fără eroare pe o colecție de 200 de qubit -uri logice. Și compania se așteaptă să o aibă la dispoziție pentru utilizare în 2029.
Poate la fel de semnificativ, IBM se angajează și la o descriere detaliată a pașilor intermediari către Starling. Acestea includ o serie de procesoare care vor fi configurate pentru a găzdui o colecție de qubit-uri corectate de erori, formând în esență o unitate de calcul funcțională. Aceasta marchează o tranziție majoră pentru companie, deoarece implică îndepărtarea de a vorbi despre colecții de qubit -uri hardware individuale și concentrarea în schimb pe unități de hardware de calcul funcțional. Dacă totul merge bine, ar trebui să fie posibil să se construiască Starling prin înlăturarea unui număr suficient de aceste unități de calcul împreună.
„Ne actualizăm [our roadmap] Acum, cu o serie de livrări care sunt foarte precise, „IBM VP Jay Gambetta a declarat pentru ARS,„ pentru că considerăm că acum am răspuns practic la toate întrebările științifice asociate cu corectarea erorilor și devine mai mult o cale către o problemă de inginerie ”.
Arhitecturi noi
Corecția erorilor pe hardware -ul cuantic implică înțelegerea unui grup de qubits într -un mod care distribuie una sau mai multe valori cuantice de biți între ele și include qubit -uri suplimentare care pot fi utilizate pentru a verifica starea sistemului. Poate fi util să ne gândim la acestea ca la qubits de date și măsurare. Efectuarea măsurătorilor cuantice slabe pe qubit -urile de măsurare produce ceea ce se numește „date sindrom”, care pot fi interpretate pentru a determina dacă s -a schimbat ceva despre qubiturile de date (indicând o eroare) și cum să o corectăm.
Există o mulțime de modalități potențiale de a aranja diferite combinații de date și qubit de măsurare pentru ca acest lucru să funcționeze, fiecare denumit cod. Dar, de regulă generală, cu atât mai multe qubit -uri hardware angajate cu codul, cu atât va fi mai robust pentru erori și cu atât mai multe qubit -uri logice care pot fi distribuite între qubit -urile sale hardware.
Unele hardware cuantice, precum cea bazată pe ioni prinși sau atomi neutri, este relativ flexibil atunci când vine vorba de găzduirea codurilor de corectare a erorilor. Qubiturile hardware pot fi mutate astfel încât oricare dintre două să poată fi încurcat, astfel încât este posibil să se adopte o gamă uriașă de configurații, deși cu prețul timpului petrecut în mișcare a atomilor. Tehnologia IBM este cu totul diferită. Se bazează pe qubit -uri realizate din electronice superconductoare așezate pe un cip, cu înțelegerea mediată de cablarea care se desfășoară între qubits. Aspectul acestui cablaj este stabilit în timpul fabricării cipului și astfel proiectarea cipului îl comite la un număr limitat de coduri potențiale de corectare a erorilor.
Din păcate, acest cablaj poate permite, de asemenea, intersecția între qubiturile vecine, determinându -i să -și piardă starea. Pentru a evita acest lucru, procesoarele IBM existente își au qubiturile conectate în ceea ce aceștia consideră o configurație „Hex Heavy”, numită pentru aranjamentele sale hexagonale de conexiuni între qubit -urile sale. Acest lucru a funcționat bine pentru a menține rata de eroare a hardware-ului său, dar reprezintă și o provocare, deoarece IBM a decis să meargă cu un cod de corecție a erorilor care este incompatibil cu geometria hexagonală grea.
Cu câțiva ani în urmă, o echipă IBM a descris un cod compact de corecție a erorilor numit o verificare a parității cu densitate mică (LDPC). Acest lucru necesită o grilă pătrată de conexiuni cele mai apropiate de vecinătate între qubit-urile sale, precum și cablarea pentru a conecta qubit-uri care sunt relativ îndepărtate pe cip. Pentru a obține cipurile și schema de corectare a erorilor în sincronizare, IBM a făcut două progrese cheie. Primul se află în ambalajul său de cipuri, care folosește acum mai multe straturi de cablare așezate deasupra Qubits -ului hardware pentru a permite toate conexiunile necesare pentru codul LDPC.
Vom vedea asta mai întâi într -un procesor numit Loon care se află pe foaia de parcurs a dezvoltării companiei. „Am demonstrat deja aceste trei lucruri: conectivitate ridicată, cupluri pe distanțe lungi și cupluri care rup avionul [of the chip] și conectați -vă la alte qubits “, a spus Gambetta.” Trebuie să le combinăm pe toate ca o singură demonstrație care arată că toate aceste părți ale ambalajelor pot fi făcute și asta vreau să obțin cu Loon. “Loon va fi făcut public la sfârșitul acestui an.
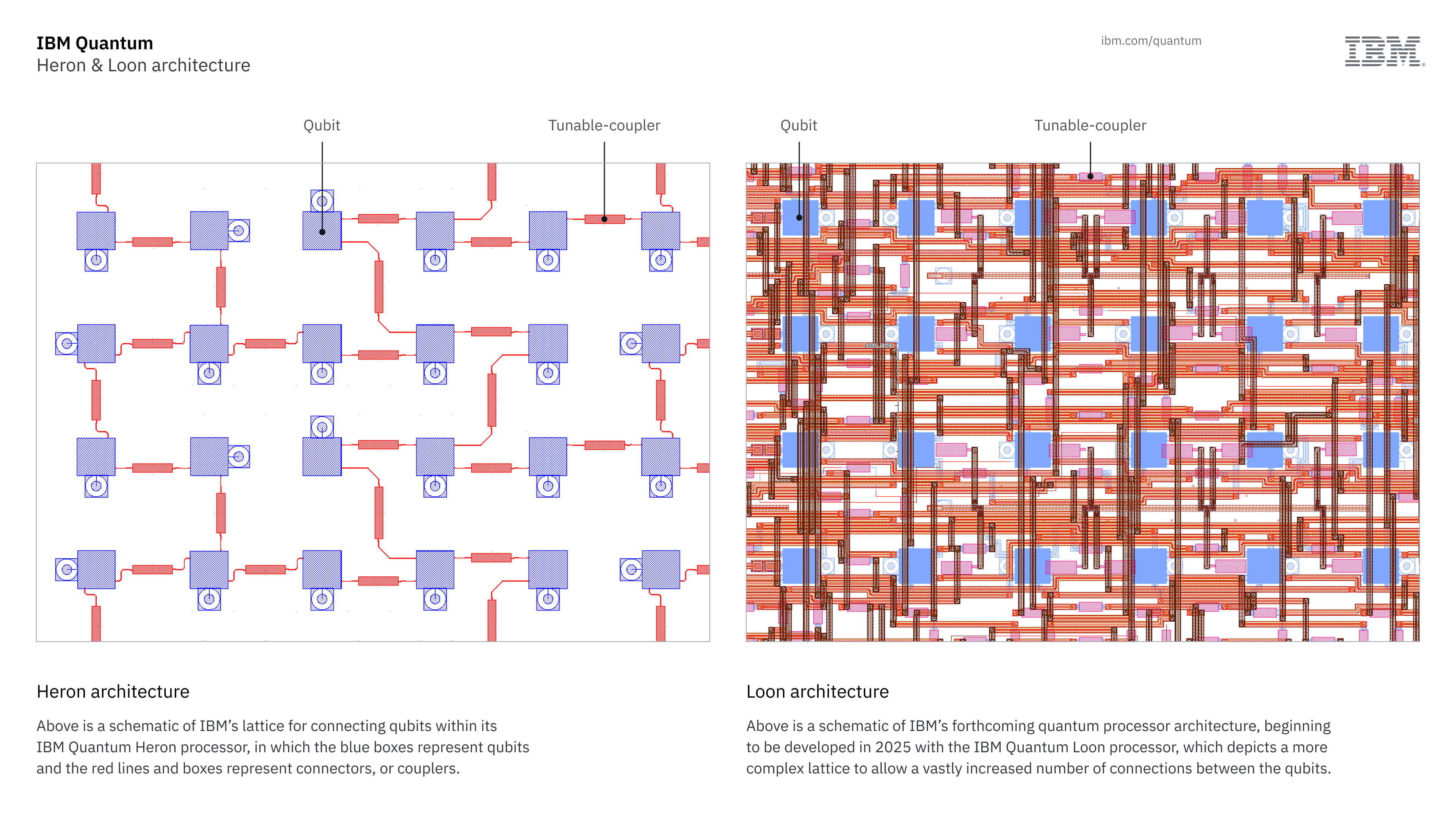
În stânga, aspectul simplu al conexiunilor într-un procesor Heron de generație curentă. În dreapta, web -ul complicat de conexiuni care vor fi prezente în Loon. Credit: IBM
Al doilea avans pe care IBM l -a făcut este să elimine interzicerea pe care geometria hexagonală grea a fost folosită pentru a minimiza, așa că hexa grea va dispărea. “Luăm anul acesta o pasăre pentru experimente pe termen scurt, care este un tablou pătrat care are aproape zero crosstalk”, a spus Gambetta, “și asta este Nighthawk”. Qubiturile mai dens conectate au tăiat cheltuielile generale necesare pentru a efectua calcule cu un factor de 15, a spus Gambetta ARS.
Nighthawk este o versiune 2025 pe o foaie de parcurs paralelă la care vă puteți gândi ca fiind orientată cu utilizatorul. Iterațiile pe designul său de bază vor fi lansate anual până în 2028, fiecare permițând mai multe operații fără eroare (trecând de la 5.000 de operațiuni de poartă în acest an la 15.000 în 2028). Fiecare procesor individual Nighthawk va găzdui 120 de qubit -uri hardware, dar 2026 va vedea trei dintre ele înlănțuite și funcționând ca unitate, oferind 360 de qubits hardware. Aceasta va fi urmată în 2027 de o mașină cu nouă procesoare Nighthawk legate, stimulând numărul de qubit hardware de peste 1.000.
Călărind cu bicicleta
Totuși, viitorul real al hardware -ului IBM se va întâmpla pe linia de dezvoltare a procesoarelor, unde discuțiile despre numărul de qubit -uri hardware va deveni din ce în ce mai irelevantă. Într -un document tehnic lansat astăzi, IBM descrie codul LDPC specific pe care îl va folosi, denumit cod de bicicletă bivariat din cauza unor simetrii cilindrice din detaliile sale care seamănă vag cu roțile de bicicletă. Detaliile conexiunilor contează mai puțin decât imaginea generală a ceea ce este nevoie pentru a utiliza acest cod de eroare în practică.
IBM descrie două implementări ale acestei forme de cod LDPC. În primul, 144 de qubit -uri hardware sunt aranjate astfel încât să joace gazdă la 12 qubit -uri logice și toate qubiturile de măsurare necesare pentru a efectua verificări de eroare. Măsura standard a capacității unui cod de a prinde și corecta erorile se numește distanța sa, iar în acest caz, distanța este 12. Ca alternativă, ei descriu și un cod care folosește 288 Qubits hardware pentru a găzdui aceleași 12 qubituri logice, dar crește distanța până la 18, ceea ce înseamnă că este mai rezistent la erori. IBM va pune la dispoziție una dintre aceste colecții de qubit -uri logice ca procesor Kookaburra în 2026, care le va folosi pentru a permite memoria cuantică stabilă.
Urmărirea le va grupa cu o mână de qubits suplimentare care pot produce state cuantice necesare pentru unele operații. Acestea, plus hardware -ul necesar pentru memoria cuantică, formează o singură unitate de calcul funcțională, construită pe un singur cip, care este capabilă să efectueze toate operațiunile necesare pentru a implementa orice algoritm cuantic.
Acest lucru va apărea cu cipul Cockatoo, care va permite, de asemenea, să fie conectate mai multe unități de procesare pe un singur autobuz, permițând numărul de qubit -uri logice să crească dincolo de 12. (Compania spune că unul dintre zeci de qubituri logice din fiecare unitate va fi utilizat pentru a media legarea cu alte unități și nu va fi disponibilă pentru calcul.) Mai multe jetoane.
Separat, IBM lansează un document care descrie o componentă cheie a sistemului care va rula pe hardware -ul de calcul clasic. Corecția completă a erorilor necesită evaluarea datelor sindromului derivate din starea tuturor qubit -urilor de măsurare pentru a determina starea qubit -urilor logice și dacă trebuie efectuate corecții. Pe măsură ce complexitatea qubiturilor logice crește, povara de calcul a evaluării crește odată cu aceasta. Dacă această evaluare nu poate fi executată în timp real, atunci devine imposibil să efectuați calcule corectate de erori.
Pentru a aborda acest lucru, IBM a dezvoltat un decodificator de trecere a mesajelor care poate efectua evaluări paralele ale datelor sindromului. Sistemul explorează mai mult din spațiul soluției printr-o combinație de randomizare a greutății oferite memoriei soluțiilor anterioare și prin predarea oricăror soluții aparent non-optime la noi cazuri pentru evaluări suplimentare. Lucrul cheie este că IBM estimează că acest lucru poate fi rulat în timp real folosind FPGA, asigurându -se că sistemul funcționează.
O arhitectură cuantică
Există, de asemenea, mult mai multe detalii dincolo de acestea. Gambetta a descris legătura dintre fiecare unitate de calcul – CIBM o numește o punte universală – ceea ce necesită un cablu cu microunde pentru fiecare distanță de cod a qubiturilor logice legate. (Cu alte cuvinte, un cod de distanță 12 ar avea nevoie de 12 cabluri care transportă cu microunde pentru a conecta fiecare cip.) El a mai spus că IBM dezvoltă hardware de control care poate funcționa în interiorul hardware-ului frigorific, pe baza a ceea ce numesc „CMO-uri reci”, care este capabil să funcționeze la 4 Kelvin.
Compania lansează, de asemenea, redarea a ceea ce se așteaptă să arate Starling: o serie de frigidere de diluare, toate conectate de o singură țeavă care conține podul universal. “Acum este o arhitectură”, a spus Gambetta. “Nu am pus niciodată detalii în foaia de parcurs pe care nu am simțit că o putem lovi, iar acum punem mult mai multe detalii.”
Lucrul izbitor pentru mine este faptul că acesta marchează o îndepărtare de la un accent pe qubit -uri individuale, conectivitatea lor și ratele de eroare ale acestora. Ratele hardware de eroare sunt acum suficient de bune (4 x 10-4) pentru ca acest lucru să funcționeze, deși Gambetta a considerat că ar trebui să se aștepte câteva îmbunătățiri. Iar conectivitatea va fi acum direcționată exclusiv către crearea unei unități de calcul funcționale.
Acestea fiind spuse, există încă mult spațiu dincolo de Starling pe foaia de parcurs a IBM. Cele 200 de qubit -uri logice pe care le promite vor fi suficiente pentru a rezolva unele probleme, dar nu sunt suficiente pentru a efectua algoritmii complexi necesari pentru a face lucruri precum criptarea pauzelor. Acest lucru va trebui să aștepte ceva mai aproape de Blue Jay, un sistem 2033 pe care IBM îl așteaptă să aibă 2.000 de qubit -uri logice. Și, de acum, este singurul lucru enumerat dincolo de Starling.

John este editorul științific al ARS Technica. Are un licențiat în arte în biochimie de la Universitatea Columbia și un doctorat. în biologie moleculară și celulară de la Universitatea din California, Berkeley. Când se desparte fizic de tastatura sa, el tinde să caute o bicicletă sau o locație pitorească pentru comunicarea cu cizmele sale de drumeție.
